Macroplot plotting is controlled by the macros in the text area provided.
Each macro must occupy its own line. If the first character of a macro is not A-Z, the line will be considered a comment and ignored
The first macro, which is obligatory, initializes the plot. The macro is
Bitmap Initialize width(in pixels), height(in pixels), red(0-255) blue(0-255), green(0-255) transparency(0-255)
Example : Bitmap Initialize 700 500 255 255 255 255 which provides a landscape area 700 pixels wide, 500 pixel high, with white background
The following are default settings when the bitmap is initiated.
Lines are black (0 0 0 255) and 3 pixels in width
Fill color for bars and dots are black (0 0 0 255), and the fill type is set to fill only (1) (see Fill Type)
Dots (circl and square) are set to 5 pixels radius (diameter=11 pixels)
Fonts are set as follows
Font face is set to sans-serif. Serif, sans-serif, and monospace are available to all browsers, user can use any font available to his/her browser
Font size is set to 16 pixels high
Font color, both line and fill are set to black (0 0 0 255), and fill type to 1 (fill only) (see Font Type)
Macros for plotting on the bitmap begin with the keyword Bitmap, and the coordinates are x=number of pixels from the left border and y=number of pixels from the top border
A central plotting area is also defined
By default, at initialization, as 15% from the left and bottom, 5% from right and top
defined by user as Plot Pixels left top right bottom, these being number of pixels from the left and top border
e.g. Plot Pixels 105 25 665 425 would be the same as the default setting for a bitmap of 700 pixels wide and 500 pixels high
The values of the data used in plotting in this central area can be defined as follows
Plot Values left top right bottom, these being the extreme values used in the data
e.g.Plot Values 0 100 10 50 represents x values of 0 on the left to 10 to the right, and y values of 50 at the bottom to 100 to the top
After the values are declared, all plotting in the central area uses macros beginning with the keyword Plot, and the coordinates are the values in the data
Macros
This panel lists and describes all macros used in this version of MacroPlot by Javascript. They are divided into the following sub-panels
Initialization and settings
Plotting areas, coordinates used, and drawing of x and y axis
Drawing lines, bars, dots, text, and other shapes
Initialization
This sub-panel lists those macros that initialized the bitmap, and set the parametrs for drawing
Initialize Plotting
Bitmap Initialize w h r g b t is the first and obligatory macro, which Initializes the bitmap
w and h are width and height of the bitmap in number of pixels. The most common dimensions are
w=700 and h= 500 for landscape orientation
w=500 and h=700 for portrait orientation
Both 500 for square bitmap
r g b t represents red, green, blue and transparency values for the background, each value is 0 for non-existence to 255 for maximum intensity. The most commonly used background is white (255 255 255 255)
For most plotting programs in StatsToDo the macro used is Bitmap Initialize 700 500 255 255 255 255, a landscape orientation with white background
Settings for lines
The settings provide parameters for all subsequent plotting until the parameter is reset
Line Color r g b t sets the line color of red, green, blue and transparency values, each value is 0 for non-existence to 255 for maximum intensity. On initialization of the bitmap, line color is lines is set by default to black (0 0 0 255)
Line Thick p sets the thickness of lines to p pixels. On initialiszation, the default setting is 3 pixels for line thickness
Settings for fills
When bars, dots, arcs and wedges are plotted, the interior of these symbols are called fills, and they are set as follows
Fill Color r g b t sets the filling color of red, green, blue and transparency values, each value is 0 for non-existence to 255 for maximum intensity. On initialization of the bitmap, fill color is lines is set by default to black (0 0 0 255).
Fill Type t sets how the fills are to be used, t can be one of the following
t=0: only the outline, defined by the line parameters, are plotted. Fill is ignored
t=1: only fill is carried out, outline is ignored
t=2: both outline and fill are plotted
When the plot is initialized, the default setting for fill type is t=1
Settings for fonts
These set the font characteristics for text output. Please note: settings for lines and fills for fonts are separate and independent to those for general line and shape plottings
Font Face name sets the font face. The program will accept all fonts supported by the user's border. The 3 fonts accepted by all browsers are serif, sans-serif, and monospace. On initialization, sans-serif is set by default
Font Style s where s can be either normal or bold. On initialization the default setting is bold
Font Size h where h is the height of the text in pixels. On initialization, the default font size is set to 16
Font Thick p where p is the thickness of the outline of the font. On initialization, this is set to p=1
Font LColor r g b t sets the color of the outline of the font. On initialization this is set to black (0 0 0 255)
Font FColor r g b t sets the fill color of the of the font. On initialization this is set to black (0 0 0 255)
Font Color r g b t sets both LColor and FColor to the same color. On initialization this is set to black (0 0 0 255)
Font Type t where t determines which part of the font is drawn, and can be one of the following
t=0: only the outline of the font, defined by the thick and LColor parameter is drawn
t=1: only the fill of the font is drawn
t=2: both outline and fill are drawn
When the plot is initialized, the default setting for Font type is t=1
Please Note: When the bitmap is initialized, the default settings, which are suitable for most situations, are automatically set, so users need not worry about these settings unless he/she has a different preference.
Axis & Coordinates
This sub-panel presents macros that define the plotting areas, and creating the x and y axis for plotting
Drawing on the bitmap
When plotting on the initialized bitmap
the horizontal coordinate x is the number of pixels from the left border
the vertical coordinate y is the number of pixels from the top border
The macro used begins with the keyword Bitmap
Drawing on the plotting area
In most cases, there is a need to draw and label the x and y axis, and drawing coordinates used are the actual values of the data. The macros used for these all begins with the keyword Plot, and are purposes are as follows
Plot Pixels lp tp rp bp defines an area for plotting
lp defines the left border of the plotting area, in the number of pixels from the left border of the bitmap. In most cases this is 15% of the bitmap's width
tp defines the top of the plotting area, in the number of pixels from the top border of the bitmap. In most cases this is 5% of the height
rp defines the right border of the plotting area, in the number of pixels from the left border of the bitmap. In most cases this is 95% of the width (or 5% from the right border of the bitmap)
bp defines the bottom border of the plotting area, in the number of pixels from the top border of the bitmap. In most cases this is 85% of the height (or 15% from the bottom)
An example is that is that, in a landscape orientated bitmap of 700 pixels width and 500 pixel height, Plot Pixels 105 25 665 425 sets the central area for plotting that is 15% from the left and bottom, and 5% from the top and right.
This macro is usually not necessary if the 5%/15% setting suits the user, as this is the default setting when the bitmap is initialized
Plot Values lv tv rv bv defines the data values to be used in plotting
lv is the extreme data value for the horizontal variable x on the left
tv is the extreme data value for the vertical variable y at the top
rv is the extreme data value for horizontal variable x on the right
bv is the extreme data value for the vertical variable y at the bottom
Plot Logx 1 sets the horizontal x axis to the log scale. Normal scale is set on initialization, or reset by Plot Logx 0
Plot Logy 1 sets the vertical y axis to the log scale. Normal scale is set on initialization, or reset by Plot Logy 0
Plot XLabel label distance places the label for the horizontal x axis, below the bottom of the plotting area
lable is a single word text string, using the underscore _ to represent spaces if necessary
space is the number of pixels between the bottom of the plot area and the label text string
Plot YLabel label distance places the label for the vertical y axis, on the left of plotting area
lable is a single word text string, using the underscore _ to represent spaces if necessary
space is the number of pixels between the left of the plot area and the label text string
The quickest and easiest way to draw axis
The following 4 macros are sufficient to draw the x and y axis under most circumstances
Plot XAxis y nsIntv nbIntv len gap line will mark out and numerate the horizontal x axis
y is the y value on which the x axis lie
nsIntv is the number of small intervals between the vertical line marks, 10 to 20 are recommended
nbIntv is the number of big intervals between the numerical scales, 5 to 10 are recommended
len is the length of the mark in pixels, +ve value downwards and negative value upwards. -10 is recommended
gap is the number of pixels between the numerical scaling text and the y value of the axis, +ve values for text below axis and negative value for text above axis. 3 is recommended
Line determines the axis line is drawn, 0 for no line, 1 for line
Plot YAxis x nsIntv nbIntv len gap line will mark out and numerate the vertical y axis
x is the x value on which the y axis lie
nsIntv is the number of small intervals between the horizontal line marks, 10 to 20 are recommended
nbIntv is the number of big intervals between the numerical scales, 5 to 10 are recommended
len is the length of the mark in pixels, +ve value to the right and negative value to the left. 10 is recommended
gap is the number of pixels between the numerical scaling text and the y value of the axis, +ve values for text to the right of axis and negative value for text to the left of axis. -3 is recommended
Line determines the axis line is drawn, 0 for no line, 1 for line
Plot AutoXLogScale y len gap line will mark and numerate the x axis if it is in log scale
The x axis must be set to the log scale by Plot Logx 1. If axis not set to log this macro will abort
y is the y value on which the x axis lie
len is the length of the mark in pixels, +ve value downwards and negative value upwards. -10 is recommended
gap is the number of pixels between the numerical scaling text and the y value of the axis, +ve values for text below axis and negative value for text above axis. 3 is recommended
Line determines the axis line is drawn, 0 for no line, 1 for line
Plot AutoYLogScale x len gap line will mark and numerate the y axis if it is in log scale
The y axis must be set to the log scale by Plot Logy 1. If axis not set to log this macro will abort
x is the x value on which the x axis lie
len is the length of the mark in pixels, +ve value downwards and negative value upwards. -10 is recommended
gap is the number of pixels between the numerical scaling text and the y value of the axis, +ve values for text below axis and negative value for text above axis. 3 is recommended
Line determines the axis line is drawn, 0 for no line, 1 for line
Other methods of drawing axis
Users may wish to draw individual part of the axis, and the following macros can be used
Plot XLine y Draws the horizontal x axis line at the y value y
Plot YLine x Draws the vertical y axis line at the x value y
Plot XMark y begin interval len marks the horizontal x axis with a series of vertical marks
y is the y value where the axis is to be marked
begin is the value for the first mark
interval is the interval between marks
len is the length of the mark line in pixels, +ve downwards, -ve upwards
Plot YMark x start interval len marks the vertical y axis with a series of horizontal marks
x is the x value where the axis is to be marked
start is the value for the first mark
interval is the interval between marks
len is the length of the mark line in pixels, +ve to the right, -ve to the left
Plot XScale y start interval gap writes the numerical scales for the horizontal x axis
y is the y value for the axis
start is the first value to be written
interval is the interval between numerical scales
gap is the space in pixels between the scale text and the axis, +ve for text below axis, -ve for text above axis
The number of decimal points in the scale is the same as that of the interval value
Plot YScale x start interval gap writes the numerical scales for the vertical y axis
x is the x value for the axis
start is the first value to be written
interval is the interval between numerical scales
gap is the space in pixels between the scale text and the axis, +ve for text to the right of axis, -ve for text to the left of axis
The number of decimal points in the scale is the same as that of the interval value
Plot XMarkIntv y interval len marks the horizontal x axis with a series of vertical marks
y is the y value of the axis
interval is the interval between the marks, beginning at 0 and while in range
len is the length of the mark line in pixels, +ve downwards, -ve upwards
Plot YMarkIntv x interval len marks the vertical y axis with a series of horizontal marks
x is the x value of the axis
interval is the interval between the marks, beginning at 0 and while in range
len is the length of the mark line in pixels, +ve to the right, -ve to the left
Plot XScaleIntv y interval gap writes the numerical scales for the horizontal x axis
y is the y value of the axis
interval is the interval between the numerical scales, beginning at 0 and while in range
gap is the space in pixels between the scale text and the axis, +ve for text below axis, -ve for text above axis
The number of decimal points in the scale is the same as that of the interval value
Plot YScaleIntv x interval gap writes the numerical scales for the vertical y axis
x is the x value of the axis
interval is the interval between the numerical scales, beginning at 0 and while in range
gap is the space in pixels between the scale text and the axis, +ve for text to the right of axis, -ve for text to the left of axis
The number of decimal points in the scale is the same as that of the interval value
Drawings
This sub-panel describes those macros that draws the plotting objects. Drawing are performed in two environments
Macros that begins with the keyword Bitmap uses pixel values as coordinates, where x is the number of pixels from the left border, and y the number of pixels from the top border
Macros that begins with the keyword Plot uses actual data values (as defined in the Plot Values lv tv rv bv macro, as coordinates
Drawing lines
The thickness and color of any line drawn is set by the Line macros (see setting sub-panel). The default setting is black line 3 pixels in width
Bitmap Line x1 y1 x2 y2 draws the line from x1y1 to x2y2
x1 and x2 are number of pixels from the left border
y1 and y2 are number of pixels from the top border
Plot Line x1 y1 x2 y2 draws the line from x1y1 to x2y2
x1 and x2 are data values for the horizontal variable x
y1 and y2 are data variables for the vertical variable y
Plot PixLine x y hpix vpix draws a line
x and y are data values for the horizonal x value and verticsl y value. This defines the coordinate at the origin of the line
hpix is the number of pixels horizontally from the origin, +ve value to the right, -ve value to the left
vpix is the number of pixels vertically from the origin, +ve value downwards, -ve value upwards
The line is then drawn between the origin and that defined by hpix and vpix
Drawing bars
The color and thickness of the outline are defined in the Line macro. The color of the fill is defined in the fill color and Fill Type macro. The default setting is black (0 0 0 255) for both line and fill color, and the Fill type is set to 1, only the fill and no outlines. These settings are suitable for most circumstances, but user can change them is so required.
Bitmap Bar x1 y1 x2 y2 draws a bar the corner of which are x1y1 and x2y2. X and y are number of pixels from the left and top border of the bitmap
Plot Bar x1 y1 x2 y2 draws a bar the corner of which are x1y1 and x2y2. X and y are data values as defined in Plot Values lv tv rv bv
Bar Wide w sets the width / height of bars for Plot VBar and Plot HBar
w is the half width of the bar, so a VBar is 2w+1 pixels in width, and HBar is 2w+1 pixels in height
The default value for w is 7 pixels (making width/height of 15 pixels), unless the user changes it
Plot VBar x y1 y2 hshift draws a vertical bar
x is the data value for the horizontal x variable. The is the center of the vertical bar
y1 and y2 are values for the vertical y variable. They define the vertical ends of the bar
hshift is the number of pixels the whole bar is shefted horizontally, +ve value to the left and +ve value to the right. In most cases this is 0 (no shift). However, if there are more than 1 bar in the same position, shifting some of them will avoid the bars overlapping and obscuring each other
The width of the vertical bar is set by default at 7, (width of bar=15 pixels)
Plot HBar x1 x2 y vshift draws a horizontal bar
x1 and x2 are data values for the horizontal x variable. They define the horizontal ends of the bar
y is the value for the vertical y variable, and defines and center of the horizontal bar
vshift is the number of pixels the whole bar is shefted vertically, -ve value upwards and +ve value downwards. In most cases this is 0 (no shift). However, if there are more than 1 bar in the same position, shifting some of them will avoid the bars overlapping and obscuring each other
Theheight of the horizontal bar is set by default at 7, (height of bar=15 pixels)
Drawing dots
There are only 2 dot types, circle and square. If more than 2 tyoes of dats are required, they can be distinguished by the colours of the outline and fill, and by their sizes. Settingsd for dot parameters are in the settings sub-panel
Bitmap Circle x y radius and Bitmap Square x y radius draws a circle or a square dot
x and y are the number of pixels from the left and top border
Radius is in number of pixels. The diameter of the dot is 2Radius+1 pixels
Plot Circle x y radius hshift vshift and Plot Square x y radius hshift vshift draws a circle or a square dot
x and y are the data values of the horizontal x variable and vertical y variable, as defined by Plot Values lv tv rv bv
Radius is in number of pixels. The diameter of the dot is 2Radius+1 pixels
hshift is the number of pixels the dot is shifted horizontally, -ve value to the left, +ve value to the right
vshift is the number of pixels the dot is shifted vertically, -ve value upwards, +ve value downwards
In most cases there is no shift (0 0), but id there are more than 1 dot in the same position, shifting avoids the dots superimposing over and obscuring each other
Dot Radius r sets the radius of the dot in pixels. The diameter of the dot is 2radius+1 pixels. The default radius is 5
Dot Type t where t is either circle or square. The default setting is circle
Plot Dot x y hshift vshift draws the dot, with its parameters (shape size color outline fill) already pre-set
x and y are the data values of the horizontal x variable and vertical y variable, as defined by Plot Values lv tv rv bv
hshift is the number of pixels the dot is shifted horizontally, -ve value to the left, +ve value to the right
vshift is the number of pixels the dot is shifted vertically, -ve value upwards, +ve value downwards
In most cases there is no shift (0 0), but if there are more than 1 dot in the same position, shifting avoids the dots superimposing over and obscuring each other
Drawing text
The color, outline, fill, font, and weight of text are preset (see settings). The default settinfs are sans-sherif, black fill only, and 16pxs high
Bitmap HText x y ha va txt draws text horizontally on the bitmap
x and y are number of pixels fom the left and top borders, and together being the reference coordinate of the text
ha is horizontal adjust
ha=0: the left end of the text is at the x coordinate
ha=1: the center of the text is at the x coordinate
ha=2: the right end of the text is at the x coordinate
va is vertical adjust
va=0: the top of the text is at the y coordinate
va=1: the center of the text is at the x coordinate
va=2: the bottom end of the text is at the x coordinate
txt is the text to be drawn. It must be a single word with no gaps. Spaces can be represented by the underscore _
Plot HText x y ha va txt hshift vshift draws text horizontally on the bitmap
x and y are data values as defined by Plot Values lv tv rv bv, and together being the reference coordinate of the text
ha is horizontal adjust
ha=0: the left end of the text is at the x coordinate
ha=1: the center of the text is at the x coordinate
ha=2: the right end of the text is at the x coordinate
va is vertical adjust
va=0: the top of the text is at the y coordinate
va=1: the center of the text is at the x coordinate
va=2: the bottom end of the text is at the x coordinate
txt is the text to be drawn. It must be a single word with no gaps. Spaces can be represented by the underscore _
hshift is the number of pixels the text is shifted horizontally, -ve value to the left, +ve value to the right
vshift is the number of pixels the text is shifted vertically, -ve value upwards, +ve value downwards
In most cases there is no shift (0 0), but if there are other structures in the same position, shifting avoids the text and structures obscuring each other
Bitmap VText x y ha va txt draws text vertically (90 degrees anticlockwise from horizontal) on the bitmap
x and y are number of pixels fom the left and top borders, and together being the reference coordinate of the text
ha is horizontal adjust
ha=0: the left end of the text is at the x coordinate
ha=1: the center of the text is at the x coordinate
ha=2: the right end of the text is at the x coordinate
va is vertical adjust
va=0: the top of the text is at the y coordinate
va=1: the center of the text is at the x coordinate
va=2: the bottom end of the text is at the x coordinate
txt is the text to be drawn. It must be a single word with no gaps. Spaces can be represented by the underscore _
Plot VText x y ha va txt hshift vshift draws text vertically (90 degrees anticlockwise from horizontal) on the bitmap
x and y are data values as defined by Plot Values lv tv rv bv, and together being the reference coordinate of the text
ha is horizontal adjust
ha=0: the left end of the text is at the x coordinate
ha=1: the center of the text is at the x coordinate
ha=2: the right end of the text is at the x coordinate
va is vertical adjust
va=0: the top of the text is at the y coordinate
va=1: the center of the text is at the x coordinate
va=2: the bottom end of the text is at the x coordinate
txt is the text to be drawn. It must be a single word with no gaps. Spaces can be represented by the underscore _
hshift is the number of pixels the text is shifted horizontally, -ve value to the left, +ve value to the right
vshift is the number of pixels the text is shifted vertically, -ve value upwards, +ve value downwards
In most cases there is no shift (0 0), but if there are other structures in the same position, shifting avoids the text and structures obscuring each other
Other miscellaneous drawings
Bitmap Arc x y radius startDeg endDeg rotate draws an arc.
x and y are number of pixels from the left and top border, and together form the center of the arc
radius is the radius of the arc, in number of pixels
startDeg and endDeg are the degrees (360 degrees in full circle) of the arc
rotate defines the direction of the arc, 0 for clockwise, 1 for anti-clockwise
Bitmap Wedge x y radius startDeg endDeg shift rotate draws a wedge, essentially an arc with lines to the center
x and y are number of pixels from the left and top border, and together form the center of the wedge
radius is the radius of the edge, in number of pixels
startDeg and endDeg are the degrees (360 degrees in full circle) of the wedge
shift is the number of pixels that the wedge is moved centrifugally (away from the center). This is used in pie charts to separate the wedges of the pie
rotate defines the direction of the wedge, 0 for clockwise, 1 for anti-clockwise
Plot Curve a b1 b2 b3 b4 b5 x1 x2 draws a polynomial curve
The curve is y=a + b1x + b2x2 + b3x3 + b4x4 + b5x5. Where higher power is not needed, 0 is used to represent the the coefficient b
The curve is drawn from data value x from x1 to x2
Plot Normal mean sd height draws a normal distribution curve
mean and sd (Standard Deviation) are as in the data horizontal variable variable x
height is the maximum height (where x=mean) of the curve as in the vertical variable y
Color Palettes
Plain Colors
0 0 0 #000000
0 0 63 #00003f
0 0 127 #00007f
0 0 191 #0000bf
0 0 255 #0000ff
0 63 0 #003f00
0 63 63 #003f3f
0 63 127 #003f7f
0 63 191 #003fbf
0 63 255 #003fff
0 127 0 #007f00
0 127 63 #007f3f
0 127 127 #007f7f
0 127 191 #007fbf
0 127 255 #007fff
0 191 0 #00bf00
0 191 63 #00bf3f
0 191 127 #00bf7f
0 191 191 #00bfbf
0 191 255 #00bfff
0 255 0 #00ff00
0 255 63 #00ff3f
0 255 127 #00ff7f
0 255 191 #00ffbf
0 255 255 #00ffff
63 0 0 #3f0000
63 0 63 #3f003f
63 0 127 #3f007f
63 0 191 #3f00bf
63 0 255 #3f00ff
63 63 0 #3f3f00
63 63 63 #3f3f3f
63 63 127 #3f3f7f
63 63 191 #3f3fbf
63 63 255 #3f3fff
63 127 0 #3f7f00
63 127 63 #3f7f3f
63 127 127 #3f7f7f
63 127 191 #3f7fbf
63 127 255 #3f7fff
63 191 0 #3fbf00
63 191 63 #3fbf3f
63 191 127 #3fbf7f
63 191 191 #3fbfbf
63 191 255 #3fbfff
63 255 0 #3fff00
63 255 63 #3fff3f
63 255 127 #3fff7f
63 255 191 #3fffbf
63 255 255 #3fffff
127 0 0 #7f0000
127 0 63 #7f003f
127 0 127 #7f007f
127 0 191 #7f00bf
127 0 255 #7f00ff
127 63 0 #7f3f00
127 63 63 #7f3f3f
127 63 127 #7f3f7f
127 63 191 #7f3fbf
127 63 255 #7f3fff
127 127 0 #7f7f00
127 127 63 #7f7f3f
127 127 127 #7f7f7f
127 127 191 #7f7fbf
127 127 255 #7f7fff
127 191 0 #7fbf00
127 191 63 #7fbf3f
127 191 127 #7fbf7f
127 191 191 #7fbfbf
127 191 255 #7fbfff
127 255 0 #7fff00
127 255 63 #7fff3f
127 255 127 #7fff7f
127 255 191 #7fffbf
127 255 255 #7fffff
191 0 0 #bf0000
191 0 63 #bf003f
191 0 127 #bf007f
191 0 191 #bf00bf
191 0 255 #bf00ff
191 63 0 #bf3f00
191 63 63 #bf3f3f
191 63 127 #bf3f7f
191 63 191 #bf3fbf
191 63 255 #bf3fff
191 127 0 #bf7f00
191 127 63 #bf7f3f
191 127 127 #bf7f7f
191 127 191 #bf7fbf
191 127 255 #bf7fff
191 191 0 #bfbf00
191 191 63 #bfbf3f
191 191 127 #bfbf7f
191 191 191 #bfbfbf
191 191 255 #bfbfff
191 255 0 #bfff00
191 255 63 #bfff3f
191 255 127 #bfff7f
191 255 191 #bfffbf
191 255 255 #bfffff
255 0 0 #ff0000
255 0 63 #ff003f
255 0 127 #ff007f
255 0 191 #ff00bf
255 0 255 #ff00ff
255 63 0 #ff3f00
255 63 63 #ff3f3f
255 63 127 #ff3f7f
255 63 191 #ff3fbf
255 63 255 #ff3fff
255 127 0 #ff7f00
255 127 63 #ff7f3f
255 127 127 #ff7f7f
255 127 191 #ff7fbf
255 127 255 #ff7fff
255 191 0 #ffbf00
255 191 63 #ffbf3f
255 191 127 #ffbf7f
255 191 191 #ffbfbf
255 191 255 #ffbfff
255 255 0 #ffff00
255 255 63 #ffff3f
255 255 127 #ffff7f
255 255 191 #ffffbf
255 255 255 #ffffff
Color Palletes
Table of colors used on this web site
255 255 255 #ffffff
224 224 224 #e0e0e0
128 128 128 #808080
128 0 0 #800000
255 0 0 #ff0000
96 48 96 #603060
48 16 64 #301040
96 96 160 #6060a0
160 160 96 #a0a060
160 160 0 #a0a000
153 191 164 #99bfa4
160 160 96 #a0a060
97 24 0 #611800
204 63 200 #cc3fc8
224 224 224 #e0e0e0
Patterns of complementary colors
A
105 93 70 #695d46
255 113 44 #ff712c
207 194 145 #cfc291
161 232 217 #a1e8d9
255 246 197 #fff6c5
B
115 0 70 #730046
201 60 0 #c93c00
232 136 1 #e88801
255 194 0 #ffc200
191 187 17 #bfbb11
C
97 24 0 #611800
140 115 39 #8c7327
71 164 41 #47a429
153 191 164 #99bfa4
242 239 189 #f2efbd
D
20 87 110 #14576e
140 33 90 #8c215a
230 133 38 #e68526
195 102 163 #c366a3
242 207 242 #f2cff2
E
64 1 1 #400101
48 115 103 #307367
96 166 133 #60a685
242 236 145 #f2ec91
229 249 186 #e5f9ba
F
55 89 21 #375915
166 60 60 #a63c3c
115 108 73 #736c49
166 157 129 #a69d81
242 224 201 #f2e0c9
G
115 36 94 #73245e
166 69 33 #a64521
217 182 78 #d9b64e
242 218 145 #f2da91
242 242 242 #f2f2f2
H
255 77 0 #ff4d00
102 87 71 #665747
125 179 0 #7db300
153 138 122 #998a7a
217 195 98 #d9c362
I
128 0 38 #800026
128 128 83 #808053
92 153 122 #5c997a
163 204 143 #a3cc8f
255 230 153 #ffe699
Explanations
Bland and Altman (1986) discussed in details how agreements between two methods of measuring the same thing can be evaluated in nuanced details. The details and terminology of the methods are described in 3 references in the reference section, and will not be repeated here.
The rest of this panel will take users through the calculations presented in the Javascript program panel
v1
v2
Mean (v1+v2)/2
Difference (v2-v1)
127
134
130.5
7
118
120
119
2
135
142
138.5
7
123
115
119
-8
112
117
114.5
5
119
123
121
4
125
125
125
0
109
111
110
2
106
122
114
16
110
115
112.5
5
111
109
110
-2
125
127
126
2
119
118
118.5
-1
140
139
139.5
-1
115
111
113
-4
110
110
110
0
122
122
122
0
119
115
117
-4
134
137
135.5
3
105
105
105
0
117
112
114.5
-5
111
113
112
2
114
115
114.5
1
126
119
122.5
-7
113
115
114
2
129
127
128
-2
130
129
129.5
-1
130
130
130
0
115
120
117.5
5
131
126
128.5
-5
Data Entry
The data is a matrix of 2 columns. Each row represents a case being measured. The two columns, separated by white space, are the paired measurements. If a gold standard is being compared, the gold standard is in the first (left) column.
The default example data on this page are generated from the computer and not real. There are only 30 pairs, too few for proper evaluation, but easier to demonstrate in this example. The data are shown in the table to the right. It represents 30 paired measurements of blood pressure. The first column (v1) is the gold standard, intra-arterial catheter, and the right (v2) the measurement being compared, external electronic cuffed manometer.
Initial Evaluation
The first step is to estimate the paired mean = (v1+v2)/2) and paired difference (v2-v1) of each pair. The original data and the estimates are presented as in the table to the right. The rest of the evaluations used the pair mean and pair difference
Statistical Evaluations
Pair Difference
Mean(Bias)=0.7667
SD=4.7828
tbias=0.878
pbias=0.3872
Regression difference=a+b(mean)
a=-0.2443
b=0.0084
tb=0.0835
pb=0.934
Number of Cases(n)
Total=30
No Diff=5
90% CIdifference = Bias ±1.6991SD
-7.3597 to 8.893
n>0=13
n<0=10
n Within 90%CI=28(93.3%)
95% CIdifference = Bias ±2.0452SD
-9.015 to 10.5484
n>0=13
n<0=11
n Within 95%CI=29(96.7%)
99% CIdifference = Bias ±2.7564SD
-12.4165 to 13.9498
n>0=13
n<0=11
n Within 99%CI=29(96.7%)
The results of the statistical evaluations are as in the table to the left
The first row is the mean and Standard Deviation of the paired difference (bias and distribution of bias), and the t test for significant departure from 0. The paired difference is named bias in the context of this evaluation. If significant bias exists (pbias<0.05) then the two measurements produced different results which has to be corrected when used.
The second row is the results of linear regression analysis where paired difference = a + b(paired mean). The regression coefficient b representws changes to paired differences related to changing paired means, and is names proportional bias . If significant proportional bias exists (pb<0.05), then the paired differences change significantly with the values of measurement, so the bias cannot be considered as stable.
The remainder of the table estimate the confidence intervals of bias. Please Note that these results differed from the common references of Bland & Altman, and Hanneman (see references) as follows
In calculation bias, Bland & Altman use bias = v1 - v2, assuming that the reference column PEER is column 2. On this page bias = v2 - v1, assuming the first column to be PEER. The results will be numerically the same, but the signs (+ and -) would be reversed
Bland & Altman offered a single confidence interval of bias ± 2 Standard Deviations.
Hanneman offered an interval of bias ± 1.96 Standard Devistions.
This table offers 3 choices, 90%, 95%, and 99% confidence intervals of bias ±t(Standard Deviations), and t are calculated as two tail p=0.1 for 90% CI, 0.05 for 95% CI, and p=0.01 for 99% CI, based on the sample size of the data. In the example from the Javascript program panel, the 95% confidence interval for the bias uses t=2.05 because the sample size of the example is 30. Bland & Altman used t=2 regardless of sample size (t=2 if p=0.05 and sample size=60), and Hanneman used 1.96 regardless of sample size (t=2 if p=0.05 and sample size=population or is infinitely large)
This table also counts the number of cases included within the 3 levels of confidence intervals
This table of analysis therefore provides the user greater details and nuances for interpretation of the results. The 95% confidence interval would be similar (though not the same) as that using algorithms suggested by Bland & Altman or by Henneman.
95% CI Precision Estimates by Bland & Altman Approximations
Sample size = 30
t for 95% CI = 2.0452
Value
Standard Error(SE)
95% CI of value
Mean Pair Difference (Bias)
0.7667
0.8732
-1.0192 to 2.5526
Upper Limit (Bias+2SD)
10.3322
1.5124
7.239 to 13.4254
Lower Limit (Bias-2SD)
-8.7988
1.5124
-11.892 to -5.7056
The results of analysis using the algorithm described in the paper by Bland & Altman are shown in the table to the right. These are presented as the Bland and Altman plot is now commonly used to evaluate agreements between measurements
Step 1, the 95% confidence, for all samples sizes, is calculated uses t=2, so that 95% CI = bias ±2SD. From the example used in the Javascript program panel
The mean is 0.7667
The Standard Deviation is 4.7828
The borders are 0.7667±2(4.7828) The bias is therefore 0.7667, and the 95% confidence interval borders -8.7988 and 10.3322
Step 2 is to calculate t, based on p=0.05 for 95% confidence interval, and the sample size of the data. In the example from the Javascript program panel, the sample size is 30, so t=2.0452. This t value is then used to calculate the precision of the mean and the 95% confidence interval borders
Step 3 is to calculate the precision of the mean bias
The Standard Error of the mean bias is sqrt(SD2/sample size)
= sqrt(4.78282/30) = 0.8732
The 95% confidence interval for precision of bias is therefore 0.7667±2x0452(0.8732),
-1.0192 to 2.5526
Step 4 is to calculate the precision of the confidence interval borders
The Standard Error of both borders are the same, being sqrt(3SD2/sample size)
= sqrt(3*4.78282/30) = 1.5124
The 95% confidence interval for precision of the borders are therefore
For the upper border, 10.3322±2.0452(1.5124) = 7.2390 to 13.4254
For the lower border, -8.7988±2.0452(1.5124) = -11.8920 to -5.7056
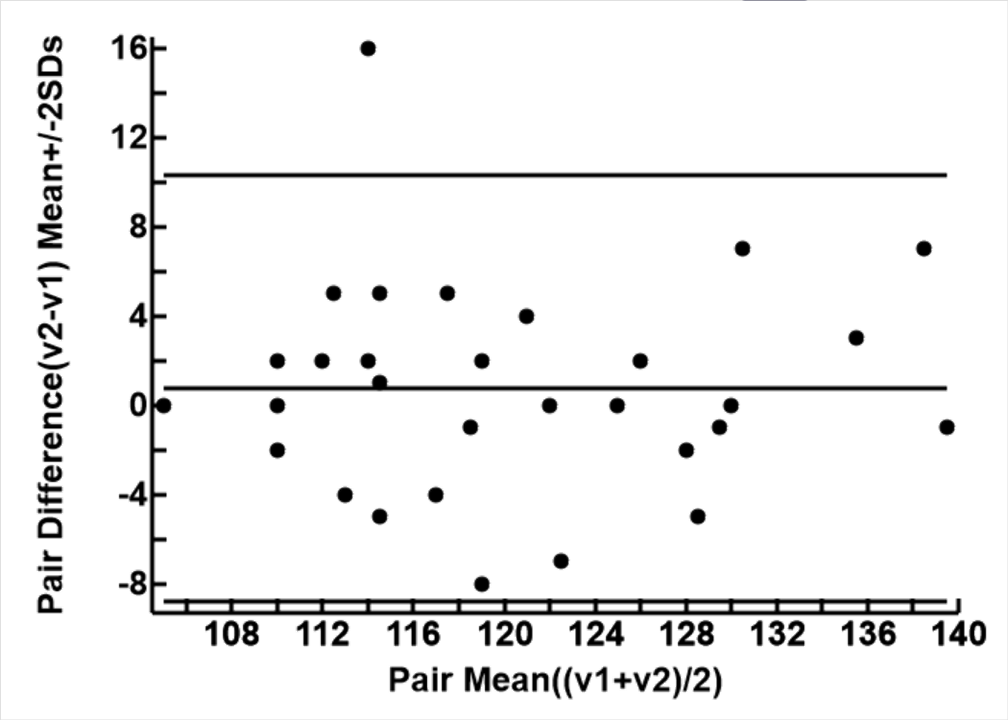
After numerical analysis, the Javascript program panel produces the Bland Altman plot, to assist the user to interpret the agreement parameters. The plot follows that described in the reference, specifically
The 3 horizontal lines are bias (mean paired difference), ± 2 x Standard Deviation of the paired difference
The black round dots are paired mean and paird difference for each case
Not calculated in the Javascript program panel
Bland and Altman (see references) suggested the duplicate or multiple measurements be taken from each case, and the variations between measurements compared with that within measurements. As these analysis represent an additional level of complexity and precision, they are not presented.
Altman DG, Bland JM (1983). "Measurement in medicine: the analysis of method comparison studies". The Statistician. 32 (3): 307-317. doi:10.2307/2987937. JSTOR 2987937.
[https://www-users.york.ac.uk/~mb55/meas/ba.pdf]
Bland JM, Altman DG (1986). "Statistical methods for assessing agreement between two methods of clinical measurement" (PDF). Lancet. 327 (8476): 307-10. https://www-users.york.ac.uk/~mb55/meas/ba.pdf
Data Entry The data is a matrix of numbers with 2 columns
- Each row a measurement subject
- The 2 columns are the paired measurements in each subject
- Measurements are assumed to be normally distributed
/span>
The R Code is translated from the Javascript code on this same page, and was initially developed to double check the arithematics
The first part are utility subroutines for formating numbers and calculate probability of t
# Decimal point output
DStr <- function (n)
{
if(is.numeric(n))
{
if(n==round(n)) return (n) # integer no change
n = sprintf("%.4f",n) # real 4 decimal points
return (sub("0+$", "", n)) # remove trailing zeroes
}
return (n) # no a number no change
}
# probability of t
TtoP<-function(t,degF,tail) #function to calculate probability from t and df
{
p = 1 - pt(t,df=degF) #probability 1 tail
if(tail==1) return (p)
return (p * 2) #orobability 2 tail
}
PtoT<-function(p,degF,tail) #function to calculate t from probability and df
{
#t = qt(1-p, df=degF) #t 1 tail
if(tail==1) return (qt(1-p, df=degF)) #t 1 tail
return (qt(1- p / 2, df=degF)) #t 2 tail
}
The main program is as follows
# Main program
dat = ("
v1 v2
127 134
118 120
135 142
123 115
112 117
119 123
125 125
109 111
106 122
110 115
111 109
125 127
119 118
140 139
115 111
110 110
122 122
119 115
134 137
105 105
117 112
111 113
114 115
126 119
113 115
129 127
130 129
130 130
115 120
131 126
")
dfm <- read.table(textConnection(dat),header=TRUE) # conversion to data frame
dfm$av <- (dfm$v1 + dfm$v2) / 2
#dfm$dif <- dfm$v1 - dfm$v2 # Bland and Altman
dfm$dif <- dfm$v2 - dfm$v1 # makes different of v2 over v1 (reference)
dfm
n = nrow(dfm)
df = n - 1
meanx = mean(dfm$av)
sdx = sd(dfm$av)
meany = mean(dfm$dif)
sdy = sd(dfm$dif)
sey = sdy / sqrt(n)
t = meany / sey;
p = TtoP(t, df, 2) * 2 # 2 tail
reg <- lm(formula = dfm$dif ~ dfm$av)
a = summary(reg)$coefficients[1,1]
b = summary(reg)$coefficients[2,1]
print(paste("n=",n,"df=",df))
print(paste("Average (x=(v1+v2)/n) mean=",DStr(meanx)," SD=", DStr(sdx)))
print(paste("Difference (bias, y = v2-v1) mean=",DStr(meany), " SD=",DStr(sdy),
" t=",DStr(t), " p=",DStr(p)))
ssqx = sdx^2 * (n-1)
ssqy = sdy^2 * (n-1)
spr = b * ssqx
rv = (ssqy-spr^2/ssqx)/(n - 2) # Residual mean Squares
seB = sqrt(rv/ssqx) # SE of slope b
tReg = b / seB
pReg = TtoP(tReg, n-2, 2) # 2 tail
print(paste("Regression y=a + bx constant a=", DStr(a)))
print(paste("Regression coefficient b=", DStr(b), " t=",DStr(tReg), " p=",DStr(pReg)))
t90 = PtoT(0.1,df,2);
t95 = PtoT(0.05,df,2);
t99 = PtoT(0.01,df,2);
p90 = meany + t90 * sdy
n90 = meany - t90 * sdy
p95 = meany + t95 * sdy
n95 = meany - t95 * sdy
p99 = meany + t99 * sdy;
n99 = meany - t99 * sdy
# counts
n00 = 0;
np90 = 0;
nn90 = 0;
np95 = 0;
nn95 = 0;
np99 = 0;
nn99 = 0;
for(i in 1:n)
{
v = dfm$dif[i]
if(v==0)
{
n00 = n00 + 1
}
else if(v>0)
{
if(v<=p90)
{
np90 = np90 + 1
}
if(v<=p95)
{
np95 = np95 + 1
}
if(v<=p99)
{
np99 = np99 + 1
}
}
else if(v<0)
{
if(v>=n90)
{
nn90 = nn90 + 1
}
if(v>=n95)
{
nn95 = nn95 + 1
}
if(v>=n99)
{
nn99 = nn99 + 1
}
}
}
print(paste("Number of cases with no difference=",n00))
nt90 = n00 + nn90 + np90
print(paste("90% CI difference = Bias +/-", DStr(t90), "SD =", DStr(n90),
" to ", DStr(p90), " n>=0 = ", np90," n<=0 =", nn90,
"n Within 90%CI=", nt90, "(", sprintf("%.1f",nt90/n*100),"%)"))
nt95 = n00 + nn95 + np95
print(paste("95% CI difference = Bias +/-", DStr(t95), "SD =", DStr(n95),
" to ", DStr(p95), " n>=0 = ", np95," n<=0 =", nn95,
"n Within 95%CI=", nt95, "(", sprintf("%.1f",nt95/n*100),"%)"))
nt99 = n00 + nn99 + np99
print(paste("99% CI difference = Bias +/-", DStr(t99), "SD =", DStr(n99),
" to ", DStr(p99), " n>=0 = ", np99," n<=0 =", nn99,
"n Within 95%CI=", nt95, "(", sprintf("%.1f",nt99/n*100),"%)"))
t = PtoT(0.05,df,2);
sey = sdy / sqrt(n)
ll = meany - t * sey;
ul = meany + t * sey;
print(paste("Precision Estimates: mean=",DStr(meany), " SE=", DStr(sey),
" 95% Confidence interval=", DStr(ll), " to ",DStr(ul)))
se = sqrt(3 * sdy^2 / n)
upper = meany + 2 * sdy
ll = upper - t * se;
ul = upper + t * se;
print(paste("Upper Limit (Bias+2SD)=",DStr(upper), " SE=", DStr(se),
" 95% Confidence interval=", DStr(ll), " to ",DStr(ul)))
lower = meany - 2 * sdy
ll = lower - t * se;
ul = lower + t * se;
print(paste("Lower Limit (Bias-2SD)=",DStr(lower), " SE=", DStr(se),
" 95% Confidence interval=", DStr(ll), " to ",DStr(ul)))
# Bland Altman Plot
plot( # Command 1: Draw dots
x = dfm$av, # x variable = average
y = dfm$dif, # y variable = difference
pch = 16, # size of dot
xlab = "Mean=(v1+v2)/2", # x label
ylab = "Diff=(v2-v1)" # y lable
)
# draw horizontal lines for mean +/- 2SD for difference = v1 - v2
abline(h=meany) # horizontal line at mean difference
abline(h=upper) # horizontal line at mean difference + 2SE
abline(h=lower) # horizontal line at mean difference - 2SE