| Content Disclaimer Copyright @2020. All Rights Reserved. |
StatsToDo: Sample Size Explained
Links : Home Index (Subjects) Contact StatsToDo
|
Explanations and References Introductionstatistical decisions became possible with the development of Type I Error by Fisher. A later improvement came through the use of Type II Error and the statistical significance model by Pearson. Pearson's model was developed with the intension of providing a statistical decision. However, it provides a theoretical framework to mathematically relate Type I Error (α), Type II Error (β), a non trivial value that represents a difference that matters, Standard Deviation (SD), and sample size. If four (4) of these parameters are known, then the fifth can be calculated.From this, the sample size required to compare two groups can be estimated if the other four (4) parameters are available. In other words, researchers are able to know the sample size they need for their results to be interpreted with confidence. Understanding this model and the availability of an objective method to calculate optimal sample size allow further development and emphasis on sample size theories and practices. At the technical level, statistical modelling allows sample size calculations to extend to data with different types of distributions (e.g., proportions, counts, time to events, ranks) and specialised research situations (e.g., phase II drug trials, post marketing trials, quality testing). From the researcher's point of view, the availability of sample size estimation greatly assists planning and evaluation of research situations. Knowledge of the appropriate sample size allows the researcher to estimate the time and resources required to complete the study and therefore, the feasibility and viability of the project. An undersized study produces either uninterpretable results or results that will not stand the test of time. On the other hand, a study larger than necessary wastes resources, inconveniences colleagues and imposes unnecessary risks and discomfort to research subjects. The absence of adequate sample size considerations therefore symbolises poor research design and indicates bad and possibly unethical research. Increasingly, if sample size considerations are inadequate, granting bodies will not support, regulating bodies will not approve, and editors of scientific publications will not accept results of the research project. The importance of sample size is discussed clearly and comprehensively by Cohen (see references) and this is very much a recommended reading. NomenclatureSample size requirement in a two group comparison depends on the four (4) parameters:
The Effect Size. Conceptually, the effect size (ES) is the difference to be detected compared with the background variation, and the sample size required is inversely related to the effect size. In other words, the smaller the difference to be detected, or larger the background variation, the larger will be the sample size required. According to Cohen, effect size for different statistical models are calculated differently
A power analysis can be carried out at the end of the study using the collected data. This checks to see whether the nominated difference and SD during planning are approximate to those actually obtained in the data, and if not how the interpretation of the data should be modified. Power analysis is particularly important if statistical decisions are based on statistical significance. A statistically not significant conclusion is validated when the power in the data collected accurately reflects that proposed during planning. With the increased use of confidence intervals, power analysis becomes less important. Much of the information for decision making is conveyed through confidence intervals. If a difference (less than which can be considered trivial) is defined along with a tolerance interval, then a conclusion can be drawn, as to whether the difference is large enough to be considered significant and/or small enough to be consider equivalent, or whether the data lacks power. One Tail or Two Tail Model One or two tail models are graphically explained in relationship to the t test in the t test Page. The following summarise the concept as it relates to sample size. In comparing two groups, a one tail model tests whether group A has a higher mean value than group B, without any consideration whether group B has higher mean value than group A. A two tail model tests whether the means from the two groups are different, without specifying which group has the higher value. Conceptually therefore, in terms of the 95% confidence interval of the difference, a one tail model is from 0% to 95%, while a two tail model is from 2.5% to 97.5% (the 5% divided equally to both sides). Sample size requirements for the one tail model is therefore very much smaller than the two tail model, but the direction of the difference needs to be pre-specified. For sample size calculations, the parameters are the same except the Type I Error, where the p value for the one tail model is twice that for the two tail model. For example, when comparing two means where the effect size (difference / SD) is 0.5, power=0.8, and Type I Error =0.05, the required sample size per group is 64. For the same study using the one tail model, an α of p=0.1 is used, and the sample size is 51 per group for Type I Error = 0.05. For power calculation, the same adjustment is required. For example, in two equal groups of 64, a finding that the difference between means is 0.5 and within group SD = 1, the power is 0.8044 for Type I Error p=0.05. For the one tail model, p=0.05 is replaced with p=0.1, so the power calculated is 0.8799 for Type I Error p=0.05 In StatsToDo, the two tail model is used for sample size and power estimation, unless otherwise specified. ReferencesCohen J (1992) A Power Primer. Psychological Bulletin Vol 112 No. 1 p. 155-159.Cohen J (1988) Statistical power analysis for the behavioral sciences. Second edition. Lawrence Erlbaum Associates, Publishers. London. ISBN 0-8058-0283-5 Machin D, Campbell M, Fayers, P, Pinol A (1997) Sample Size Tables for Clinical Studies. Second Ed. Blackwell Science IBSN 0-86542-870-0. Chapter 1, p. 1 - 10 provides a detailed and clear explanation of sample size and power, and within it, in section 1.3.5 in p. 4, a short but authoritative explanation of the one and two tail model Chinn S (2000) A simple method for converting an odds ratio to effect size for use in meta-analysis. Statistics in medicine 19:3127-3131 Lancaster GA, Dodd S, Williamson PR (2010) Design and analysis of pilot studies: recommendations for good practice. Journal of Evaluation in Clinical Practice 10:2 p307-312 Johanson GA and Brooks GP (2010) Initial Scale Development: Sample Size for Pilot Studies. Educational and Psychological Measurement 70:3 p.394-400 Parametric MeasurementsThe precision of sample size calculation depends very much on a known and accurate population or within group Standard Deviation. The difficulty is that this Standard Deviation is mostly unknown. Most users use published Standard Deviations, but these are obtained by sampling, so they contain errors.One way to get around the difficulty is to realise that sample size calculation is not so much based on the within group Standard Deviation, but on the Effect Size, which is a ratio of the difference to be detected and the within group Standard Deviation. Cohen, in his 1992 paper, suggested that for most research situations, an approximate estimation of the required Effect Size can be nominated, from which an approximate sample size can be determined. Using sample size per group in a two group analysis of variance as a demonstration model, the arguments are as follows.
Non-parametric MeasurementsA number of procedures to estimate sample size requirements for nonparametric comparisons have been proposed, but most of them are suitable only for specific circumstances, and difficult to use generally. For example, sample size for nonparametric paired and unpaired scales are available, but they require users to define the number of ranks in the data, and model the proportion of the groups in each rank. These procedures are therefore not presented in StatsToDo.Instead, an approximation of the sample size requirement can be computed, using an assumption of normal distribution. Users are cautioned however that this is only an approximation, and many statisticians do not approved of this approach, as by the very nature of nonparametric measurements, any assumption of normal distribution incorporates an unknown error. For those who nevertheless need to calculate a sample size, the algorithm and its reasoning are as follows
Sample Size CalculationSample size calculations are carried out at the planning stage of a research project, and is based on 3 parameters
Power EstimationAs explained in the probability explanations page, the use of statistical significance has been increasingly criticised, because the estimation of background Standard Deviation are so often not correct. Increasingly, the data obtained is examined, to evaluate its power. In this context power is the probability that to reject the null hypothesis is correct, or the ability to detect a difference if it really exists.Research results with an insufficiently large effect size will show a probability of Type I Error that is too large to reject the null hypothesis (α>0.05). However the effect size is a ratio of the effect (e.g. difference between two groups) and the background variation (e.g. within group Standard Deviation). If the effect (e.g. difference between two groups) is less than the critical value proposed during research planning, then the correct conclusion that it is too small to be statistically significant can be made. However, if the effect is adequate, but the background variation (e.g. within group Standard Deviation) is larger than that envisaged during planning, then the research design, execution, or both are flawed, and no statistical conclusion can be drawn. Power estimate allows the researcher to determine whether the power from the data collected is comparable to that during planning (e.g. power=0.8). If the power is inadequate, the researcher can make the decision whether to abandon the results, or to collect more data until the power reaches the level planned. Confidence IntervalsThe confidence interval is another method of evaluating data collected without making any assumptions other than normal distribution. Usually the 95% confidence interval estimated from the effect and it's Standard Error, and the null hypothesis rejected if this interval does not overlaps the null value.Pilot studiesPilot studies are conducted for two main reasons. The first is to test the feasibility and organisational structure of a research project, and the second to establish some ball park figures for population parameters and what the results are likely to be, which can be used in the planning of the main research project.The reference section lists two excellent papers on pilot studies, and those interested should read these papers to get greater detail and insight into pilot studies than can be provided in this introduction. The remainder of this section addresses sample size for pilot studies, adapted from the descriptions provided by Johanson and Brooks (2010). In hypothesis testing, sample size is estimated according to the tolerance of Type I and Type II Errors, so that the results can be interpreted with confidence. For a pilot study however, the aim is to obtain some ball park figures of what the main research project is likely to find, so the sample size required depends on a balance between the precision that can be achieved and the cost incurred in data collection. In other words, there is a diminishing return, with smaller and smaller improvements in precision as sample size increases. In planning a pilot study, the researcher has to make a value judgement as to when a very small further improvement in precision is no longer worth the much greater costs of a further increase in sample size. This decision is based on when the sample size/confidence interval curve flattens out, and in most cases this occurs when the sample size is between 10 and 40 cases. An Example
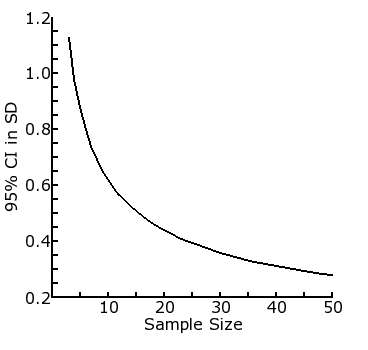
This example shows the use of sample size estimation in a pilot study, based on the confidence interval of a difference between two means, calculated using the algorithm in the SSiz2Means.php page. The example here is to examine the 95% confidence interval of the effect size in terms of difference between two means / Standard Deviation units (which is the same as difference between two means if the background SD is 1). The table shows the relationship between increasing sample size (col 1) and the efficiency (col 5). This relationship can also be shown as a plot between the first 2 columns of the table, as in the figure below.
It can be seen from the table that the 95% CI decreases from 0.88 SD units with a sample size of 5 to 0.80 with sample size of 6, a decrease of 0.08 SDs (9% of 0.88). However, the 95% CI decreases from 0.39 SD units with a sample size of 25 to 0.38 with a sample size of 26, a decrease of 0.01 (2% of 0.39) which is very much smaller than that occurring at the sample size of 5-6 level. In other words, there is a diminishing return, with smaller and smaller improvements in precision as sample size increases. The researcher can therefore reasonably make a decision in this case that a sample size no larger than between 5 and 10 per group would be appropriate for the pilot study, as further increases only improve the precision of the study trivially. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||